

画像生成AIの流れ
AIの研究はすでに様々な企業がおこなっていて、画像を生成するAI自体も以前から存在はしていました。
しかし、ここ数ヶ月での画像生成AIの台頭は皆さんもご存じかもしれませんが、絵を描く人間にとっても無視できないものとなっています。なにが起きたのでしょう。
まず、Discordが発表したMidjourneyはとても話題になりました。
言葉を打ち込みしばらく待つと、それらしい画像が出てきます。
そのクオリティがすばらしく、いうなれば魔法のようでした。
ただ、このサービスを商用利用するためには月額制の会員になる必要があり、Discordのアプリ内での使用になるため機能や使い方としても限定的な面はややありました。
次に頭角をあらわしたのが、Stable Diffusionです。
Stable Diffusionのなによりも革新的だった点はオープンソースだったということです。
ソースコードが公開されていて、それをもとにカスタマイズされたアプリが次々に開発されていきます。
LINEで言葉を打つと画像が出力されるものや、スマホアプリの「AIピカソ」、アニメチックなイラストで記憶に新しい「NovelAI」。これらはすべてStable Diffusionを基に作られています。
現在の画像生成AIの大きな流れの中心にあるのは、Stable Diffusionの存在だといえます。
大まかな機能は「txt2img」と「img2img」
Stable Diffusion Web UI(本家から使いやすく作られたやつ)を用いて、目玉といえる機能のtxt2imgとimg2imgについて解説します。
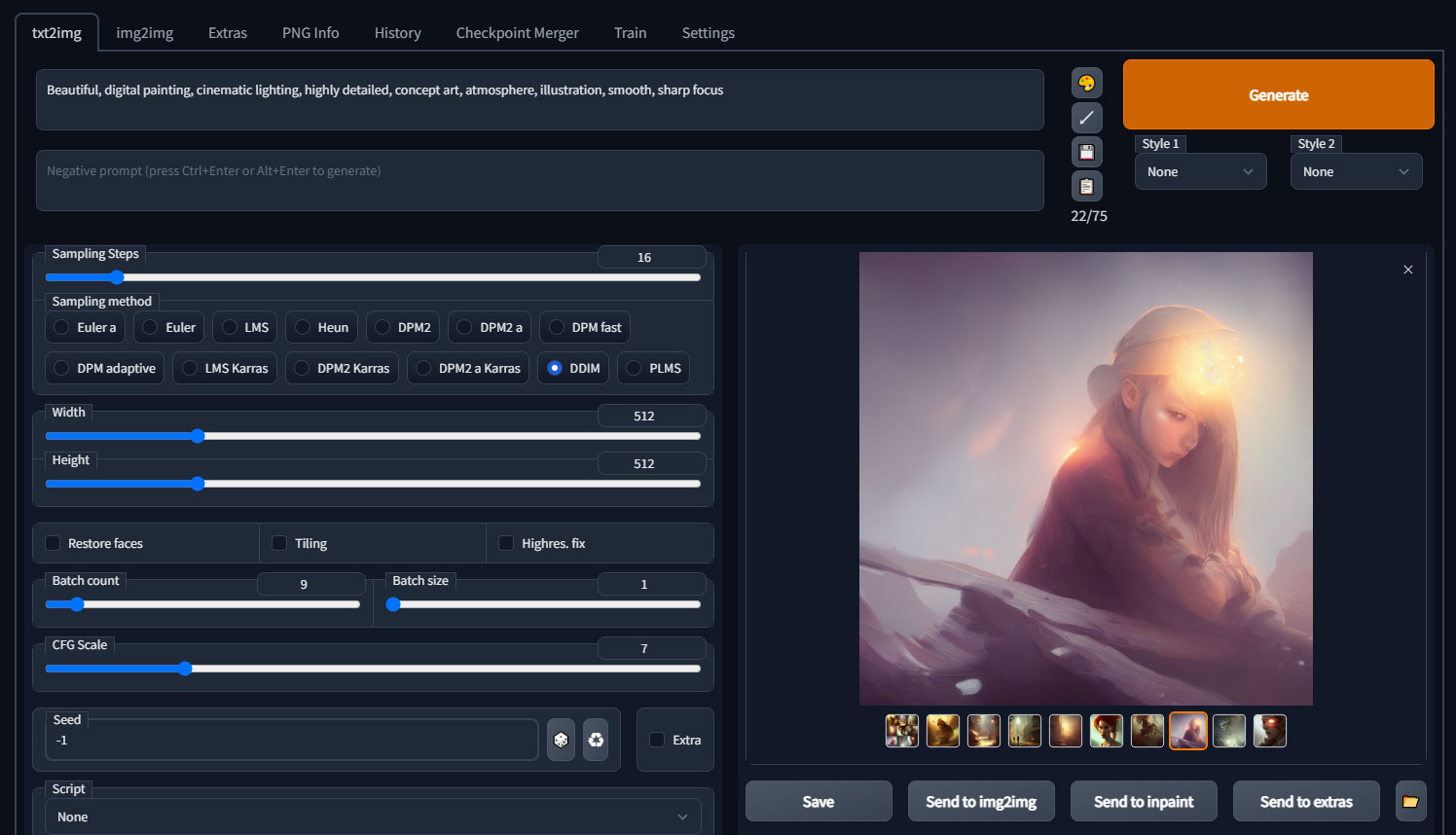
txt2img
txt2imgは「text to image」のことで、文章から画像に変換するということですね。
上部の枠の中に英語で、書き出したい画像を伝えて、Generateボタンをクリックすると画像が出てきます。
img2img
img2imgは「image to image」ですね。画像を基に新たな画像を出力します。
左の枠で基にしたい画像を指定して、Generateです。このときも上部の枠には言葉での入力があった方がより狙った画像になりやすいです。
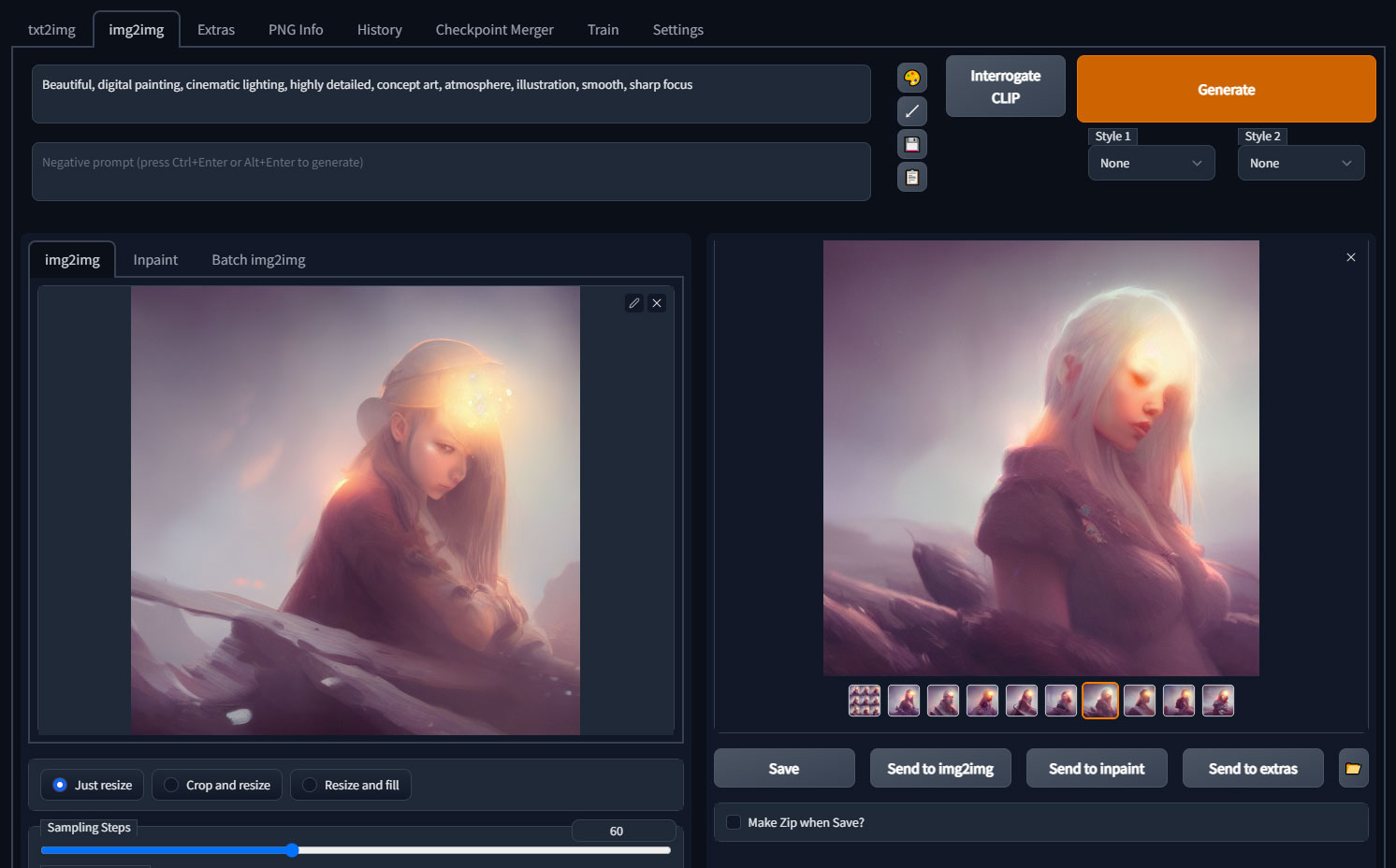
作例の画像では、テキストを基に生成された画像から、さらに右側の画像を生成しています。
実際、このような手順で画像のクオリティを上げていくというやり方は多いです。
画像生成AIの実用的な運用方法
- 背景に使う
- 小物や看板・ポスターなど背景素材の一部に使う
- 下絵にして自分で描く
絵を描く人想定で、いま簡単に想像できる利用方法はこの3つです。
もちろんこれ以外にも絵の制作方法や、アイデアの工夫などで使い方はまだまだあると思います。
画像生成AIを使ってみて気になったのは、良い感じの画像が出力されるのに運が絡むことです。
究極の一枚を出そうとすると、出るまで回し続けるしかありません。それには時間がかかるのでかなりの忍耐力を要します。
これには現実的な解決方法があり、描ける部分は自分で描くことです。それを言い出すと元も子もない感じもしますが、AIによって出力された画像に修正を入れたり加筆したりするのは、効率の良いやり方になると思います。
画像生成AIにできないこと
それはずばり、良い絵を選ぶことです。
いま画像生成AIによるポピュラーな手順は、まず精度の低い絵をたくさん書き出します。
その中から、自分が良さそうだなと思う画像を選び、img2imgで画像を書き出していき、最終的に好きな画像を選びます。
画像の選定は必ず人の意思によって行われています。その部分がAIを用いた画像生成における人間のもっとも大きな役割となっているのです。そういった意味でその都度操作は必要になるので、首尾AIに任せてすばらしい絵が完成するというわけではありません。
なぜAIが良い絵を判断できないのかというと、定義があいまいだからです。
漠然とした良い絵の条件は、前後関係や条件、あるいは個人の好みや気分によって変わります。それは優れた計算力を持つコンピュータを持ってしても、解析がむずかしいのです。
かなり条件を絞って、どんな絵が人に選ばれるかのデータをとっていけば、人の好みの最大公約数的な画像はAIも学習できるかもしれませんが。
人体の手の部分や、特定のキャラを絵柄を保って描くのが苦手だといわれていますが、細部の精度であれば今後のアップデートや学習などで克服できるのではないかと思っています。
現状でもネガティブプロンプトで対策するなど、工夫のやり方もあるようです。
画像生成AIの問題点
使う際の問題点(ハードル)
- グラフィック性能が結構必要
- プログラミングや英語の理解が時に必要
Stable Diffusionを手持ちのPCで動かすにはグラフィックボードが必要になります。それもVramが重要で最低8GB、10GB以上が望ましい、スピードや解像度を上げるためにはさらに! という感じです。
私もまさかこんなことになるとは思っていなかったので、いまはGTX1650(4GB)を使っていて、設定とかもいじってギリ最低の解像度が書き出せる感じなので、4GBは実用的ではありません。
急遽、RTX3060(12GB)を注文しました。(本当はiPadを買おうと思っていたお金で!)

一応、オンラインでStable Diffusionを使う方法もあって、Google Colaboratoryというサービスは大変便利です。無料でもお試し的に使えます。
しかし、オンライン上でStable Diffusionの環境を作るのは、知識的なハードルはやや高くなります。
人が作ってくれたテンプレートみたいなのを流用することもできるのですが、エラーが出たときや、ちょっとカスタマイズしたいときに詰みます。
Stable Diffusionは大部分がプログラミング言語のPythonによって書かれているらしいので、その知識や英語を読む能力があると、トラブルを解決したり、最新の情報にアクセスすることができるかもしれません。そこらへんは私も勉強中です。
権利や法律の問題点
それから、権利や法律の問題もあります。
いまのようなAIのために専用で作られた法律というものはまだないでしょう。
今後、制定されて、なんらかの制限が設けられるかもしれません。
権利としては、アメリカでAIが作った作品には著作権がないという判決が下されたらしいです。その事例ではほとんど人の手が加わっていないということがポイントのようで、AIをあくまで素材として用いて、人が描いた絵には著作権が生じることになると思われます。
画像生成AIをはじめて触った感想とこれから

これははじめてAIに描いてもらった画像です。私もこの時はまだその能力に懐疑的でした。
かなり勉強して、使いこなせればすごいことになるかもしれないと、次第に気づいてきました。
万能ではないけれど、指示をうまく出せば、すごい絵を描いてくれる助っ人になるかもしれないと感じています。

現状、AIには問題があることもたしかですが、大きな流れとして私たちの生活に溶け込むようになっていくことはたしかなように思われます。画像生成に限らず、さまざまな分野でそうなっていくでしょう。
これを悲観的に思う人もあるかもしれませんが、あくまで制作方法のオプションが一つ増えたと考えれば、ポジティブにとらえることもできるかもしれません。
具体的な制作の手順も次の記事にするかもです。
